
开云体育这成为DeepSeek历练本钱低最要津的原因-开云官网kaiyun切尔西赞助商 「中国」官方网站 登录入口
文 | 新浪科技 周文猛开云体育 1月27日,DeepSeek应用登顶苹果好意思国地区应用商店免费App下载排名榜,在好意思区下载榜上高出了ChatGPT。同日,苹果中国区应用商店免费榜自满,DeepSeek成为中国区第一。 DeepSeek究竟历害在那儿? 当天,中国工程院院士、清华大学探讨机系讲明注解郑纬民及多位AI圈东说念主士在与新浪科技换取中,指出了DeepSeek其获胜出圈的要津方位。 当今,业界关于DeepSeek的怜爱与惊叹,主要围聚在三个方面。第一,在技能层面,DeepSeek
-

文 | 新浪科技 周文猛开云体育
1月27日,DeepSeek应用登顶苹果好意思国地区应用商店免费App下载排名榜,在好意思区下载榜上高出了ChatGPT。同日,苹果中国区应用商店免费榜自满,DeepSeek成为中国区第一。
DeepSeek究竟历害在那儿?
当天,中国工程院院士、清华大学探讨机系讲明注解郑纬民及多位AI圈东说念主士在与新浪科技换取中,指出了DeepSeek其获胜出圈的要津方位。
当今,业界关于DeepSeek的怜爱与惊叹,主要围聚在三个方面。第一,在技能层面,DeepSeek背后的DeepSeek-V3及公司新近推出的DeepSeek-R1两款模子,区分已毕了并列OpenAI 4o和o1模子的身手。第二,DeepSeek研发的这两款模子本钱更低,仅为OpenAI 4o和o1模子的十分之一傍边。第三,DeepSeek把这一两大模子的技能齐开源了,这让更多的AI团队,冒失基于最先进同期本钱最低的模子,拓荒更多的AI原生应用。
那么,DeepSeek是若何已毕模子本钱的裁汰的呢?
郑纬民指出,“DeepSeek自研的MLA架构和DeepSeek MOE架构,为其自己的模子历练本钱下落,起到了要津作用。”他指出,“MLA主要通过纠正瞩眼力算子压缩了KV Cache大小,已毕了在通常容量下不错存储更多的KV Cache,该架构和DeepSeek-V3模子中FFN 层的纠正相投作,已毕了一个相配大的稀少MoE 层,这成为DeepSeek历练本钱低最要津的原因。”
就技能层面而言,KV Cache是一种优化技能,常被用于存储东说念主工智能模子运行时产生的token的键值对(即key- value数值),以提高探讨后果。具体而言,在模子运算进程中,KV cache会在模子运算进程中充任一个内存库的扮装,以存储模子之前处理过的token键值,通过模子运总探讨出瞩眼力分数,有用适度被存储token的输入输出,通过“以存换算”幸免了大批大模子运算每次齐是从第一个token初始运算的相通探讨,提高了算力使用后果。
此外,据郑纬民露馅,DeepSeek还措置了“相配大同期相配稀少的MoE模子”使用的性能清苦,而这也成了“DeepSeek历练本钱低最要津的原因”。
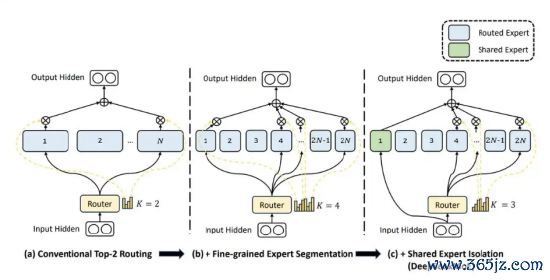
当今,通过MoE搀杂巨匠模子提高AI大模子的专科瓦解身手正成为业界公认的有用技能,并且一个大模子的巨匠模子数目越多,模子就越稀少,后果也越高,但巨匠模子变多可能导致最毕生成的松手不太准确。
据郑纬民先容,“DeepSeek相比历害的是历练MoE的身手,成为公开MoE模子历练中第一个能历练获胜这样大MoE的企业。”新浪科技了解到,为保证大范围MoE巨匠模子的平衡运行,DeepSeek使用了先进的、不需要赞成吃亏函数的、巨匠加载平衡技能,保证每个token下,小数巨匠网罗参数被真确激活的情况下,不同的巨匠网罗冒失以更平衡的频率被激活,瞩目巨匠网罗激活扎堆。
此外,DeepSeek还充分诳骗巨匠网罗被稀少激活的策画,铁心了每个token被发送往GPU集群节点(node)的数目,这使得GPU之间通讯支拨沉稳在较低的水位。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
背负裁剪:常福强 开云体育